4.Machine Learning¶
Assignment¶
- Fit a machine learning model to your data
Prompt (ChatGPT)
What is Machine Learning in data science?
Answer
Machine learning in data science is the field where computers learn patterns from data and make predictions or decisions without being explicitly programmed for each task.Here’s a simple explanation:
What it is
Machine learning (ML) is a technique used in data science that allows algorithms to learn from data. Instead of writing rules manually, you feed the machine a lot of examples, and it learns the rules by itself.
What it does
Machine learning can:
- Predict future values (e.g., sales, temperatures)
- Classify things (e.g., spam or not spam)
- Recognize patterns (e.g., faces, voices)
- Make decisions (e.g., recommend a movie)
Words¶
XOR Example¶
XOR stands for “exclusive OR"
Definition
XOR outputs 1 only when the two inputs are different.
If the inputs are the same, it outputs 0.
| Input A |
Input B |
Output A XOR B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Why is XOR “historically important”?
Because a single linear model (like a single-layer perceptron) cannot learn XOR. Its data points cannot be separated with a straight line.
perceptron¶
The perceptron is the most basic model of an artificial neural network and serves as the origin of modern machine learning and deep learning.
back propagation¶
誤差の逆伝播
- essential algorithm to propagate errors back through the network to perform the weight updates
activation functions¶
有効化機能
- sigmoid(シグモイド関数)
- Map any input to a value between 0 and 1
- good for binary output
- tanh (双曲正接)
- Map the input to a value between -1 and 1
- good for internal layers
- ReLU (正規化線形ユニット)
- Map negative inputs to 0 while leaving positive inputs unchanged
- fixes vanishing gradients, easier to compute

Ref. IBM back propagation
JAX¶
JAX is is a Python library for accelerator-oriented array computation and program transformation, designed for high-performance numerical computing and large-scale machine learning.
It supports reverse-mode differentiation (a.k.a. backpropagation) via jax.grad as well as forward-mode differentiation, and the two can be composed arbitrarily to any order.
MNIST¶
Modified National Institute of Standards and Technology (Modified-NIST)
| Feature | NIST | MNIST |
|---|---|---|
| Purpose | Designed for postal code recognition (practical use) | For research and education (machine learning beginner-friendly) |
| Writers | Training: NIST staff Test: high school students |
Mixed writers from staff and students; random distribution for fairness |
| Image Size | Varies | Normalized to 28×28 pixels |
| Preprocessing | Minimal or none; inconsistent | Centered, size-normalized, contrast-adjusted |
| Usability | Harder to use directly | Ready to use for machine learning |
| Data Format | Multiple formats, complex | Unified format: train-images, train-labels, test-images, test-labels |
| Training/Test Split | Different writer distributions | Balanced and randomized split between training and test sets |
LLM¶
As day 1 assignment, I have chosen GDXray - X-ray images for X-ray testing and Computer Vision.
GDXray+
GDXray+ (the GRIMA X-ray database) is a public database consisting of more than 21,100 X-ray images collected for X-ray inspection and computer vision research.
GDXray includes five groups of images as you can see from here
- Baggages
- Castings
- Nature
- Settings
- Welds
as you can see from here
I have chosen "Baggages".
Baggages.zip (3.41GB) In this dataset,
- 86 objects
- each object has 10-20 photos from different angles
- apploxmetry 1290 photos
What I want to do¶
Use LLM to create a JAX program that learns from the Baggage images.
But in this assignment, I will use two objects(800 + 144 pictures)
Two objects¶
Prompt (ChatGPT)
Write a minimal JAX program using no other libraries, to train a neural network to classify the X-ray data sets, saved from this repository (datasets/Baggages), and using matplotlib to show a few samples of the training data and fits
Answer
Below
#GPT-5 mini.
import os
import random
import numpy as np
import jax
import jax.numpy as jnp
from jax import grad, jit
import matplotlib.pyplot as plt
from PIL import Image
# --- Load dataset ---
def load_images(folder, size=(64,64)):
images, labels, class_names = [], [], sorted(os.listdir(folder))
class_to_idx = {name: i for i, name in enumerate(class_names)}
for class_name in class_names:
class_folder = os.path.join(folder, class_name)
for file in os.listdir(class_folder):
if file.endswith('.png') or file.endswith('.jpg'):
img = Image.open(os.path.join(class_folder, file)).convert('L')
img = img.resize(size)
images.append(np.array(img)/255.0)
labels.append(class_to_idx[class_name])
return np.array(images), np.array(labels), class_names
images, labels, class_names = load_images("datasets/Baggages")
images = images.reshape(len(images), -1) # Flatten
labels_onehot = jnp.eye(len(class_names))[labels]
# --- Visualize a few samples ---
plt.figure(figsize=(8,4))
for i in range(6):
idx = random.randint(0, len(images)-1)
plt.subplot(2,3,i+1)
plt.imshow(images[idx].reshape(64,64), cmap='gray')
plt.title(class_names[labels[idx]])
plt.axis('off')
plt.show()
# --- Simple neural network ---
def init_params(layer_sizes, key):
params = []
keys = jax.random.split(key, len(layer_sizes))
for i in range(len(layer_sizes)-1):
W = jax.random.normal(keys[i], (layer_sizes[i], layer_sizes[i+1])) * 0.1
b = jnp.zeros(layer_sizes[i+1])
params.append((W, b))
return params
def forward(params, x):
for W, b in params[:-1]:
x = jnp.tanh(jnp.dot(x, W) + b)
W, b = params[-1]
logits = jnp.dot(x, W) + b
return jax.nn.softmax(logits)
def loss_fn(params, x, y):
pred = forward(params, x)
return -jnp.mean(jnp.sum(y * jnp.log(pred + 1e-8), axis=1))
grad_loss = jit(grad(loss_fn))
# --- Training ---
layer_sizes = [64*64, 128, len(class_names)]
params = init_params(layer_sizes, jax.random.PRNGKey(0))
lr = 0.01
for step in range(200):
grads = grad_loss(params, images, labels_onehot)
params = [(W - lr*dW, b - lr*db) for (W,b), (dW,db) in zip(params, grads)]
if step % 50 == 0:
print(f"Step {step}, loss={loss_fn(params, images, labels_onehot):.4f}")
# --- Show predictions for a few samples ---
plt.figure(figsize=(8,4))
for i in range(6):
idx = random.randint(0, len(images)-1)
plt.subplot(2,3,i+1)
plt.imshow(images[idx].reshape(64,64), cmap='gray')
pred_class = class_names[int(jnp.argmax(forward(params, images[idx])))]
plt.title(f"Pred: {pred_class}")
plt.axis('off')
plt.show()

Step 0, loss=1.0022 Step 50, loss=0.3333 Step 100, loss=0.2596 Step 150, loss=0.2173

This is the resulting image, just in case it is not shown above.
{kind=link}
One object only¶
with open("datasets/Baggages/B0055/labels.txt") as f:
lines = f.readlines()
print("Number of label lines:", len(lines))
Number of label lines: 200
import glob
files = sorted(glob.glob("datasets/Baggages/B0055/*.png"))
print("Number of images:", len(files))
Number of images: 503
Number of label lines and images doen't match, so I decided to use only labeled images.
Labeled images only¶
Pronpt(ChatGPT)
with open("datasets/Baggages/B0055/labels.txt") as f:
lines = f.readlines()
print("Number of label lines:", len(lines))
Number of label lines: 200
import glob
files = sorted(glob.glob("datasets/Baggages/B0055/*.png"))
print("Number of images:", len(files))
Number of images: 503
labels.txt is like below: 1.0000000e+00 1.0000000e+00 0.0000000e+00 0.0000000e+00 2.0000000e+00
Use only labeled images. Write a minimal JAX program using no other libraries, to train a neural network to classify the X-ray data sets, saved from this repository (datasets/Baggages/B0055), and using matplotlib to show a few samples of the training data and fits
Answer Below:
# train_baggages_jax.py
# Minimal JAX training script for datasets/Baggages/B0055
# Requires: jax, matplotlib
import os
import glob
import random
from math import ceil
import jax
import jax.numpy as jnp
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# -------- config --------
DATA_DIR = "datasets/Baggages/B0055"
LABELS_FILE = os.path.join(DATA_DIR, "labels.txt")
IMG_GLOB = os.path.join(DATA_DIR, "*.png")
seed = 0
hidden = 128
lr = 0.1
batch_size = 32
epochs = 80
print_every = 10
# ------------------------
key = jax.random.PRNGKey(seed)
# Load labels (one-per-line; scientific notation strings like "1.0000000e+00")
with open(LABELS_FILE, "r") as f:
label_lines = [ln.strip() for ln in f.readlines() if ln.strip() != ""]
labels = [int(float(x)) for x in label_lines] # convert to ints
n_labeled = len(labels)
print("Number of label lines:", n_labeled)
# Load image file list and keep only first n_labeled sorted files
files = sorted(glob.glob(IMG_GLOB))
print("Number of image files found:", len(files))
files = files[:n_labeled]
print("Using first", len(files), "images (matching labels)")
# Helper: load image using matplotlib.image.imread (returns HxWxC floats or HxW)
def load_image_as_gray(path):
img = mpimg.imread(path) # float in [0,1] for PNG
if img.ndim == 3:
# if 4 channels (RGBA) or 3 (RGB), average channels to grayscale
img = img[..., :3] if img.shape[2] >= 3 else img
img = img.mean(axis=2)
return img.astype("f4")
# Load all images into a list then stack into an array
imgs = [load_image_as_gray(p) for p in files]
# Check sizes; if variable sizes exist, resize by simple center-crop or pad to median shape.
shapes = [im.shape for im in imgs]
if len(set(shapes)) != 1:
# find median shape and simple center-crop/pad to that
heights = sorted([s[0] for s in shapes])
widths = sorted([s[1] for s in shapes])
H = heights[len(heights)//2]
W = widths[len(widths)//2]
def crop_or_pad(im, H, W):
h, w = im.shape
# crop center
start_h = max(0, (h - H)//2)
start_w = max(0, (w - W)//2)
cropped = im[start_h:start_h+H, start_w:start_w+W]
# pad if too small
out = jnp.zeros((H,W), dtype=jnp.float32)
ch, cw = cropped.shape
out = out.at[0:ch, 0:cw].set(cropped)
return out
imgs = [jnp.array(crop_or_pad(im, H, W)) for im in imgs]
print("Normalized images to shape", (H,W))
else:
H,W = shapes[0]
imgs = [jnp.array(im) for im in imgs]
print("All images same shape:", (H,W))
# Flatten images and build dataset arrays
X = jnp.stack([im.reshape(-1) for im in imgs]) # shape (N, H*W)
y = jnp.array(labels) # shape (N,)
num_classes = int(jnp.max(y)) + 1
print("Num classes inferred:", num_classes)
N, D = X.shape
print("Dataset:", N, "samples x", D, "features")
# Simple MLP utilities (two-layer)
def init_mlp_params(key, sizes):
params = []
keys = jax.random.split(key, len(sizes)-1)
for k, (n_in, n_out) in zip(keys, zip(sizes[:-1], sizes[1:])):
w_key, b_key = jax.random.split(k)
# xavier init
W = jax.random.normal(w_key, (n_in, n_out)) * jnp.sqrt(2.0/(n_in + n_out))
b = jnp.zeros((n_out,))
params.append((W, b))
return params
def mlp_forward(params, x):
# x: (batch, D)
h = x
*hidden_layers, (Wlast, blast) = params
for (W,b) in hidden_layers:
h = jnp.tanh(jnp.dot(h, W) + b)
logits = jnp.dot(h, Wlast) + blast
return logits
def onehot(labels, num_classes):
return jnp.eye(num_classes)[labels]
def loss_fn(params, batch_x, batch_y):
logits = mlp_forward(params, batch_x)
# softmax cross entropy
labels_oh = onehot(batch_y, num_classes)
logp = jax.nn.log_softmax(logits)
loss = -jnp.mean(jnp.sum(labels_oh * logp, axis=1))
return loss
# Init model
sizes = [D, hidden, num_classes]
key, subk = jax.random.split(key)
params = init_mlp_params(subk, sizes)
# Training helpers
@jax.jit
def update(params, x_b, y_b, lr):
grads = jax.grad(loss_fn)(params, x_b, y_b)
new_params = []
for (W,b), (gW, gb) in zip(params, grads):
new_params.append((W - lr * gW, b - lr * gb))
return new_params
def batch_iter(X, y, batch_size, key):
N = X.shape[0]
perm = jax.random.permutation(key, N)
Xs = X[perm]
ys = y[perm]
for i in range(0, N, batch_size):
yield Xs[i:i+batch_size], ys[i:i+batch_size]
# Quick function to compute accuracy
@jax.jit
def predict(params, x):
logits = mlp_forward(params, x)
return jnp.argmax(logits, axis=1)
@jax.jit
def eval_loss(params, X, y):
return loss_fn(params, X, y)
# Training loop
for epoch in range(1, epochs+1):
key, sk = jax.random.split(key)
for x_b, y_b in batch_iter(X, y, batch_size, sk):
params = update(params, x_b, y_b, lr)
if epoch % print_every == 0 or epoch == 1 or epoch == epochs:
l = float(eval_loss(params, X, y))
preds = predict(params, X)
acc = float(jnp.mean(preds == y))
print(f"Epoch {epoch:3d} loss={l:.4f} acc={acc*100:.2f}%")
# Show a few samples with predictions
num_show = min(12, N)
idxs = random.sample(range(N), num_show)
idxs = jnp.array(idxs)
fig, axes = plt.subplots(3, 4, figsize=(10,7))
axes = axes.ravel()
preds = predict(params, X[idxs])
for ax, i, p in zip(axes, idxs, preds):
img = X[i].reshape(H, W)
ax.imshow(img, cmap="gray")
ax.set_title(f"label={int(y[i])} pred={int(p)}")
ax.axis("off")
plt.suptitle("Samples: label vs predicted")
plt.tight_layout()
plt.show()
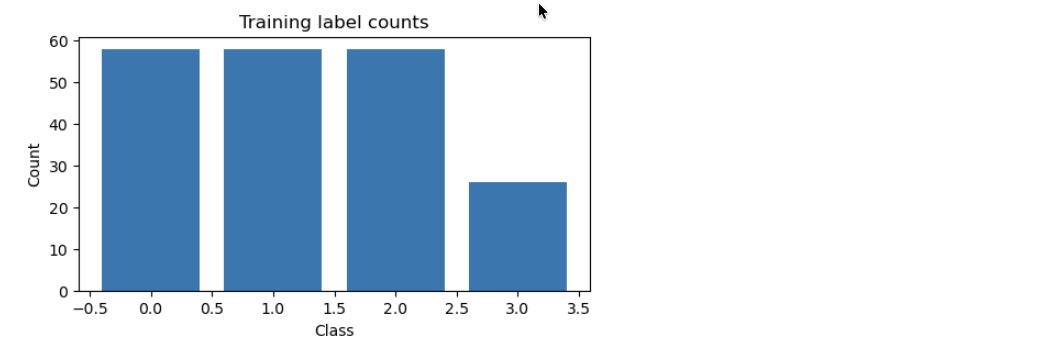
# Plot training data class distribution (simple)
plt.figure(figsize=(6,3))
vals, counts = jnp.unique(y, return_counts=True)
plt.bar([int(v) for v in vals], counts)
plt.xlabel("Class")
plt.ylabel("Count")
plt.title("Training label counts")
plt.show()
Number of label lines: 200 Number of image files found: 503 Using first 200 images (matching labels) Normalized images to shape (121, 121) Num classes inferred: 4 Dataset: 200 samples x 14641 features Epoch 1 loss=3.8870 acc=29.00% Epoch 10 loss=2.2593 acc=29.00% Epoch 20 loss=1.5407 acc=30.50% Epoch 30 loss=1.9797 acc=31.00% Epoch 40 loss=1.7045 acc=38.50% Epoch 50 loss=2.2031 acc=32.00% Epoch 60 loss=2.4911 acc=36.00% Epoch 70 loss=1.3751 acc=35.00% Epoch 80 loss=1.5877 acc=34.50%


This is the result
{kind=link}
{kind=link}
I asked ChatGPT ...
Pronpt(ChatGPT)
What does the result mean?
Answer
Answe is below
This result indicates that the model is not learning effectively. It is unstable and close to random-level accuracy.
Main reasons:
- Only 200 training samples → too small
- High-dimensional input → hard to train with small data
- Small MLP → cannot capture image patterns well
- Learning rate may be too high → unstable loss
Simple suggestions for improvement
- Resize images to smaller size (e.g., 32×32 → 1024 features)
- Reduce learning rate (e.g., lr=0.01 → 0.001)
- Increase network size (e.g., [14641 → 512 → 128 → 4])
- Increase number of epochs (e.g., 500 instead of 80)
- Use a Convolutional Neural Network (CNN) → more suitable for image classification
Pronpt(ChatGPT)
Include all the suggestions for improvement and rewrite the code
Answer
The answer is below
# train_baggages_jax_cnn_fixed.py
import os
import glob
import random
import jax
import jax.numpy as jnp
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# -------- config --------
DATA_DIR = "datasets/Baggages/B0055"
LABELS_FILE = os.path.join(DATA_DIR, "labels.txt")
IMG_GLOB = os.path.join(DATA_DIR, "*.png")
seed = 0
lr = 0.001
batch_size = 32
epochs = 500
print_every = 20
TARGET_H, TARGET_W = 32, 32
CHANNELS = 1
key = jax.random.PRNGKey(seed)
# -------- Load labels --------
with open(LABELS_FILE, "r") as f:
label_lines = [ln.strip() for ln in f.readlines() if ln.strip() != ""]
labels = [int(float(x)) for x in label_lines]
n_labeled = len(labels)
print("Number of label lines:", n_labeled)
# -------- Load & resize images --------
files = sorted(glob.glob(IMG_GLOB))[:n_labeled]
def load_image_as_gray(path):
img = mpimg.imread(path)
if img.ndim == 3:
img = img[..., :3].mean(axis=2)
return img.astype("f4")
def resize_image(im, new_h, new_w):
h, w = im.shape
row_idx = (jnp.arange(new_h) * (h / new_h)).astype(int)
col_idx = (jnp.arange(new_w) * (w / new_w)).astype(int)
return im[row_idx[:, None], col_idx[None, :]]
imgs = [resize_image(load_image_as_gray(p), TARGET_H, TARGET_W) for p in files]
X = jnp.stack([im[..., None] for im in imgs]) # shape (N,H,W,C)
y = jnp.array(labels)
N = X.shape[0]
num_classes = int(jnp.max(y)) + 1
print(f"Dataset: {N} samples x {TARGET_H}x{TARGET_W}x{CHANNELS}, num_classes={num_classes}")
# -------- CNN Utilities --------
def conv2d(x, w, b, stride=1):
# NHWC convolution
x = jax.lax.conv_general_dilated(
lhs=x,
rhs=w,
window_strides=(stride,stride),
padding="SAME",
dimension_numbers=("NHWC","HWIO","NHWC")
)
return x + b
def relu(x):
return jnp.maximum(0, x)
def flatten(x):
return x.reshape((x.shape[0], -1))
def onehot(labels, num_classes):
return jnp.eye(num_classes)[labels]
# -------- Initialize CNN parameters --------
def init_cnn_params(key):
keys = jax.random.split(key, 5)
params = {}
# Conv1: 3x3, 1->16
params['W1'] = jax.random.normal(keys[0], (3,3,1,16)) * jnp.sqrt(2/(3*3*1))
params['b1'] = jnp.zeros((16,))
# Conv2: 3x3, 16->32
params['W2'] = jax.random.normal(keys[1], (3,3,16,32)) * jnp.sqrt(2/(3*3*16))
params['b2'] = jnp.zeros((32,))
# Fully connected: 32*32*32 -> 512 -> 128 -> num_classes
fc_input = TARGET_H * TARGET_W * 32
params['W3'] = jax.random.normal(keys[2], (fc_input,512)) * jnp.sqrt(2/fc_input)
params['b3'] = jnp.zeros((512,))
params['W4'] = jax.random.normal(keys[3], (512,128)) * jnp.sqrt(2/512)
params['b4'] = jnp.zeros((128,))
params['W5'] = jax.random.normal(keys[4], (128,num_classes)) * jnp.sqrt(2/128)
params['b5'] = jnp.zeros((num_classes,))
return params
# -------- CNN forward --------
def cnn_forward(params, x):
x = relu(conv2d(x, params['W1'], params['b1']))
x = relu(conv2d(x, params['W2'], params['b2']))
x = flatten(x)
x = relu(jnp.dot(x, params['W3']) + params['b3'])
x = relu(jnp.dot(x, params['W4']) + params['b4'])
logits = jnp.dot(x, params['W5']) + params['b5']
return logits
# -------- Loss & accuracy --------
def loss_fn(params, x, y):
logits = cnn_forward(params, x)
labels_oh = onehot(y, num_classes)
logp = jax.nn.log_softmax(logits)
return -jnp.mean(jnp.sum(labels_oh * logp, axis=1))
@jax.jit
def predict(params, x):
return jnp.argmax(cnn_forward(params, x), axis=1)
@jax.jit
def update(params, x, y, lr):
grads = jax.grad(loss_fn)(params, x, y)
return {k: params[k] - lr*grads[k] for k in params}
def batch_iter(X, y, batch_size, key):
N = X.shape[0]
perm = jax.random.permutation(key, N)
for i in range(0,N,batch_size):
idx = perm[i:i+batch_size]
yield X[idx], y[idx]
# -------- Initialize parameters --------
params = init_cnn_params(key)
# -------- Training loop --------
for epoch in range(1, epochs+1):
key, sk = jax.random.split(key)
for x_b, y_b in batch_iter(X, y, batch_size, sk):
params = update(params, x_b, y_b, lr)
if epoch % print_every == 0 or epoch == 1 or epoch == epochs:
l = float(loss_fn(params, X, y))
acc = float(jnp.mean(predict(params,X)==y))
print(f"Epoch {epoch:3d} loss={l:.4f} acc={acc*100:.2f}%")
# -------- Show some samples (fixed JAX indexing) --------
num_show = min(12, N)
# use jnp.array instead of Python list
idxs = jnp.array(random.sample(range(N), num_show))
# get predictions
preds = predict(params, X[idxs])
# plot
fig, axes = plt.subplots(3, 4, figsize=(10,7))
axes = axes.ravel()
for ax, i, p in zip(axes, idxs, preds):
# convert index to int for indexing y and displaying
idx_int = int(i)
img = X[idx_int, ..., 0] # NHWC -> take first channel
ax.imshow(img, cmap='gray')
ax.set_title(f"label={int(y[idx_int])} pred={int(p)}")
ax.axis("off")
plt.suptitle("Samples: label vs predicted")
plt.tight_layout()
plt.show()
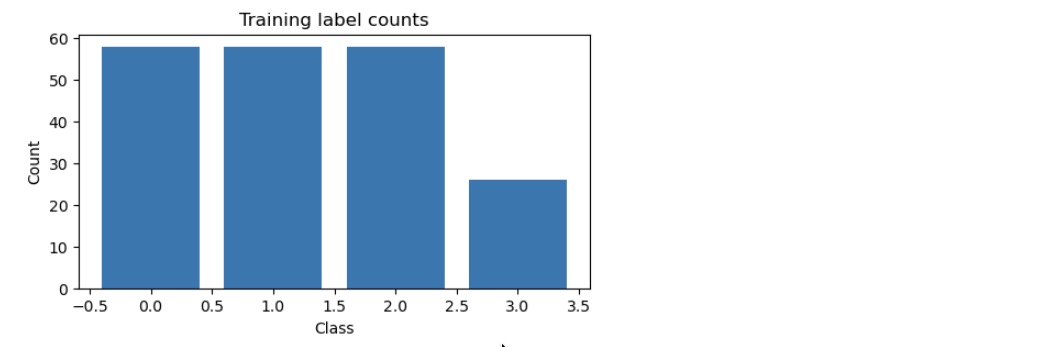
# Plot training data class distribution (simple)
plt.figure(figsize=(6,3))
vals, counts = jnp.unique(y, return_counts=True)
plt.bar([int(v) for v in vals], counts)
plt.xlabel("Class")
plt.ylabel("Count")
plt.title("Training label counts")
plt.show()
Number of label lines: 200 Dataset: 200 samples x 32x32x1, num_classes=4 Epoch 1 loss=1.3416 acc=32.00% Epoch 20 loss=1.3560 acc=38.00% Epoch 40 loss=1.3554 acc=43.50% Epoch 60 loss=1.1438 acc=51.50% Epoch 80 loss=1.4220 acc=24.00% Epoch 100 loss=1.6295 acc=33.00% Epoch 120 loss=1.1524 acc=47.50% Epoch 140 loss=1.1535 acc=44.00% Epoch 160 loss=0.9092 acc=67.00% Epoch 180 loss=0.8702 acc=65.50% Epoch 200 loss=0.9837 acc=52.00% Epoch 220 loss=0.8279 acc=66.50% Epoch 240 loss=1.0394 acc=46.50% Epoch 260 loss=0.7587 acc=70.00% Epoch 280 loss=0.7975 acc=66.00% Epoch 300 loss=0.9730 acc=52.00% Epoch 320 loss=0.7428 acc=69.00% Epoch 340 loss=0.7072 acc=72.50% Epoch 360 loss=0.7635 acc=67.50% Epoch 380 loss=0.7899 acc=66.00% Epoch 400 loss=0.6013 acc=76.50% Epoch 420 loss=0.9127 acc=57.50% Epoch 440 loss=0.5660 acc=80.00% Epoch 460 loss=0.8700 acc=57.50% Epoch 480 loss=0.7741 acc=68.00% Epoch 500 loss=0.7572 acc=67.50%

This is the result
{kind=link}
{kind=link}
Pronpt(ChatGPT)
What does the result mean?
Answer
Answer is below
Observed Trends
Accuracy is low in the first few epochs (30–40%) - The model starts close to random, so initial predictions are poor.
Accuracy improves in the middle epochs (50–70%)
- The CNN is learning image features and classification performance is improving.
Maximum accuracy reaches 80% in later epochs - The model successfully learns some patterns in the images. - However, because the dataset is small (200 images), the accuracy is not perfect.
Fluctuations in loss and accuracy - A decreasing loss indicates the model is making more correct predictions. - Occasional drops in accuracy are due to the small dataset and possibly a still relatively high learning rate.
⸻
Summary
- The model is learning, but the dataset is small, so stable, high accuracy cannot be achieved.
- Even with 32×32 images and a simple CNN, the model can learn some features.
- To further improve accuracy:
- Apply data augmentation (rotation, flip, etc.)
- Increase image size slightly
- Add more layers to the CNN
- Watch out for overfitting since 500 epochs may be excessive for a small dataset
- In short, this training result shows that the model can learn to classify the 4 classes, but the small dataset leads to unstable accuracy.